The Research Data Lifecycle
For most research projects, data follows a similar lifecycle, where a plan is made to collect the data, it is processed ready for analysis, and it is later shared or published, and ultimately decisions are made about whether the data will be preserved so it can be accessed and used later. Data that is shared may be reused and used in the planning of future research, and therefore the cycle continues, as shown in the diagram below. Many versions of this diagram exist, often with variations to show how data collection, processing and analysis are repetitive tasks in many projects, and also to show how other processes relating to data such as data curation or data storage fit into the data lifecycle.
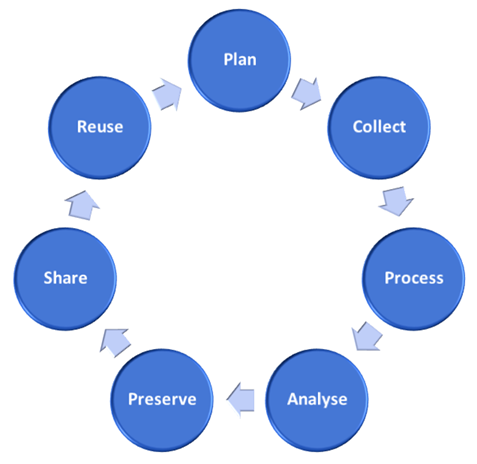
The stages of the lifecycle do not necessarily happen in the same order in each project, and as mentioned, some stages may also be repeated.
Planning
It is important to consider how data will be captured, organised, used, stored, shared and reused right at the beginning of the project. Data that is not effectively managed is likely to be disorganised, difficult to use and reuse, and potentially even impossible to find. A Data Management Plan is a formal document that is often used to help with planning the management of research data by providing a template of questions to prompt thinking about these topics. It is also important to consider how you will capture information about the data you are collecting and how it will be transformed throughout the lifecycle. This stage is also where decisions should be made about how the research data will be stored during and after the end of the project, and both how and where the data will be shared and who can use the data and for what purposes. For projects that collect sensitive data or use human or animal subjects, ethical and privacy considerations will need to be made.
Collection
The collection stage describes when new data is being collected or generated during the research, for example through experimentation or computational techniques as mentioned above. The data output from this stage is usually considered to be the raw data that feeds into the other stages. Metadata also needs to be collected that describes the data, along with other records of the research such as observations, methods and protocols, code and software, workflows and notes captured in paper or digital notebooks. Metadata that describes the data and what has happened to it is essential for understanding the data and its provenance. Research data, metadata and associated documentation need to be managed and safely stored during the project.
Processing
Digital data typically needs to be processed before it is analysed:
- Data cleaning - to identify any errors in the data, deal with any missing data, and remove any duplicates
- Data reduction - remove any data that is not required for the analysis
- Data validation - to ensure that the data is accurate and is consistent with expected values
- Data transformation - scaling data to facilitate comparison, changing format to enable analysis with chosen code and software, adding additional context to the data from external sources
- Data integration - merging with data from other sources to create a cohesive data set, matching with data from other sources to align the data
- Data annotation - adding labels or annotations, often for use in machine-learning The data output from this stage is often thought of as intermediate or active data and needs to be managed and safely stored in the same way as the raw data. There may be different versions or iterations of the data as different techniques are applied to prepare the data for analysis.
Analysing
Data may be analysed using a variety of different techniques most commonly using calculations, specialist analysis software or computational analysis. The data is often transformed from numerical format to graphical form through visualisation techniques. The outputs of the analysis stage are often the results data that will be shared in reports or formal academic publications. During this stage there may be different versions and iterations of the data as different analysis techniques are applied, especially where the research is focused on finding new or improving scientific processes. It is important that documentation and metadata is captured that describes the
Preserving
Research data needs to be safely stored during the project, but it is also important to consider how it will be preserved in the long term. It may not be necessary to keep all of the data, but decisions may also be dependant on local regulations and institutional or funder policies. For example, it may be a requirement that you store your research data for a minimum period of time. If your research includes sensitive, personal or information subject to intellectual property agreements there may be more stringent requirements about protecting the data, as well as where, how, and for how long you must store the data. Repositories or databases are typically used for the long term preservation of data, but considerations need to be given to where to the data is deposited, who is responsible for the curation of that data, and who becomes responsible for the data once it has been deposited.
Sharing
Research data may be shared to different extents during different parts of the project, for example your research data may be used or validated by others in your research group, or collaborators from the wider community during the collection, processing, and analysis stages. For Open Science, the research data may be shared from the very beginning of the lifecycle, for example through the use of Open Notebooks and through regular deposits of data into public repositories. The sharing stage, in the research data lifecycle typically refers to the point in the project where the research is formally published and the data is shared to the scientific community as a whole. Although historically the research data shared with scholarly publications has been limited to summary results tables and images such as spectra in the Supplementary Information, there is a drive by funders and the community to share more data publicly. This includes encouraging the sharing of raw data and the code and workflows used to generate the results data in appropriate repositories so that the data can be validated and reused by others. An important part of sharing data is choosing what to share, where to share it, ensuring it is properly documented so others can understand it, and applying a license to make it clear how it can be used and how to cite it.
Reusing
The final stage is reusing the research data shared by others. Many researchers are dependant upon access to the data provided by others for their own research, especially for computational techniques and applications of machine-learning, but many researchers need to be able to compare or combine their own with existing datasets. Any data that is reused needs to be documented carefully so that the appropriate attribution can be given to credit the researchers who collected and analysed the data. If data is shared without appropriate metadata, documentation and license it will be impossible to use because it can not be understood, or the availability of the data to be reused for particular purposes will not be apparent. The reusing stage feeds into the planning stage, because any new project needs to consider if and how it will make use of existing shared datasets as part of the project.
What to do next
- Learn about research data
- Learn about data management planning
- Find out how to get help with research data management
Related links:
- Creator: Cerys Willoughby, Louise Saul
- Last modified date: 2026-01-27
- License: CC-BY-4.0
- Citation: Please cite: Cerys Willoughby and Louise Saul, The Research Data Lifecycle, https://guidance.psdi.ac.uk/docusaurus-pages/docs/guidance/data-management/data-life-cycle/, PSDI (modified 2026-01-27)
If you would like to contribute content to the PSDI Knowledge Base or have feedback you would like to give on this guidance, please contact us.